Five Algorithms in a Linked List
Part I
在这部分,中我们将要介绍链表的最简单的两种算法 - 头插法和尾插法。
顾名思义,头插法和尾插法就是在链表头部或者尾部进行结点的插入操作。
如果觉得直接看代码略有些吃力,可以滑到文末的图解处,配合小结文字先行理解。
链表结点
首先,我们先给出链表结点的结构定义。
typedef struct node {
Elemtype data;
struct node* next;
} Lnode;
解释
Elemtype是元素的类型,比如说int、char之类;
next则是指向下一个结点的指针;next的类型是struct node*,
其中*表示的是这是一个指针,struct node是该指针指向的数据类型。
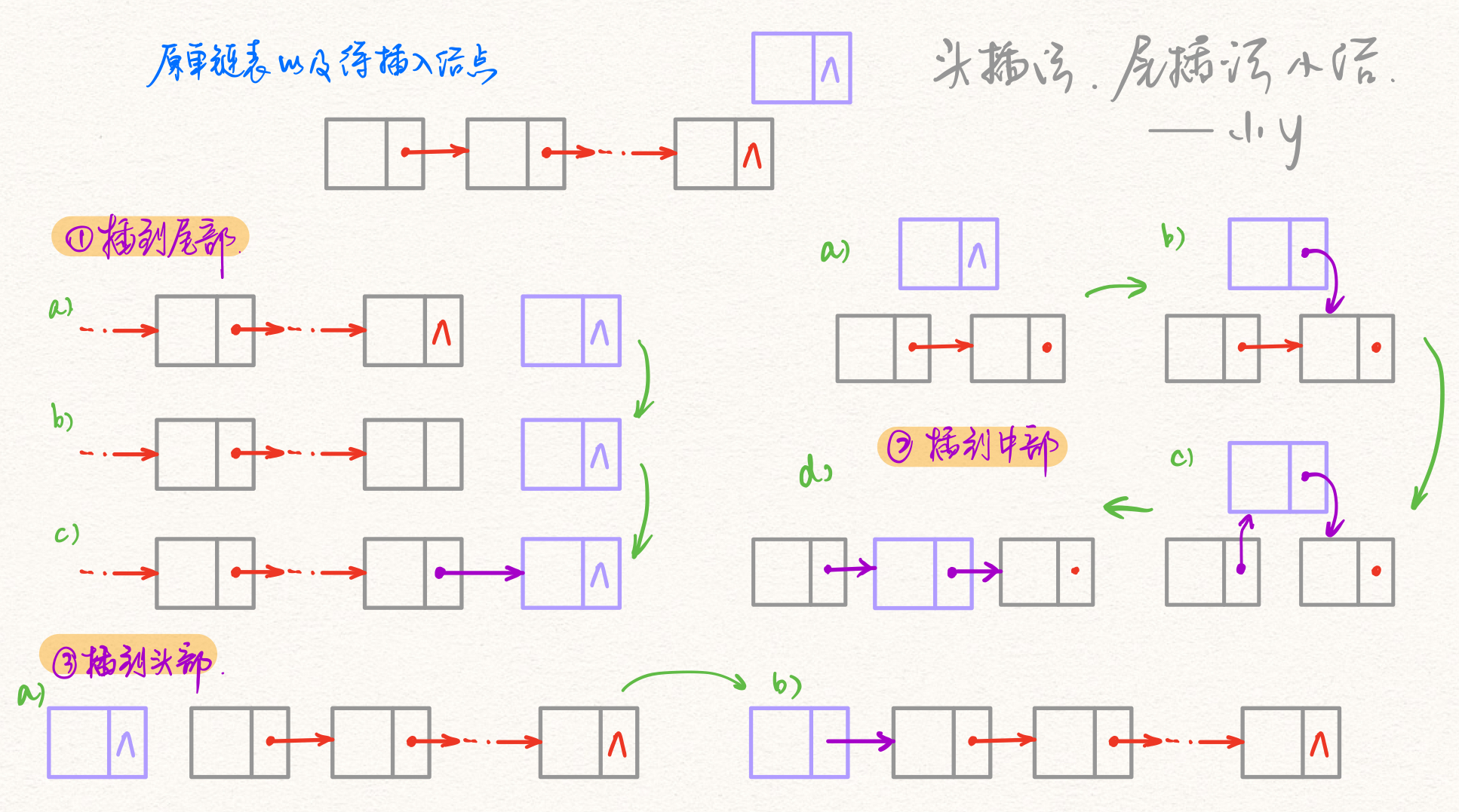
一、头插法
头插法就是在链表头部插入元素。
因为链表的头结点往往给出,所以我们在头部进行结点的插入操作时,一般只需要考虑是否存在头结点的情况;另外考虑是否返回头结点,所以一共分为四种情况。
具体代码实现如下:
Lnode* insert_in_head1(Linklist& L, Lnode* p) {
// if head node exit
// insert the node in the head of the list
// return the head node
p->next = L->next;
L->next = p;
return L;
}
Lnode* insert_in_head2(Linklist& L, Lnode* p) {
// if head node not exit
// insert the node in the front of the list
// return the first node
p->next = L;
return L;
}
void insert_in_head3(Linklist& L, Lnode* p) {
// if head node exit
// insert the node in the head of the list
p->next = L->next;
L->next = p;
}
void insert_in_head4(Linklist& L, Lnode* p) {
// if head node not exit
// insert the node in the front of the list
p->next = L;
L = p;
}
二、尾插法
因为单链表并不具有随机存取的特点,而给出的链表常常只是给出头结点,而在尾部插入势必需要知道当前尾部结点的位置(不然找不到位置,你插那儿呢)。
一般来说,我们只能通过遍历的方式,来获得链表尾部结点的位置(此操作时间复杂度为O(n), 空间复杂度为O(1))。
在下面不同情况的代码实现中,分为了在知道单链表头结点的情况下,是否知道尾结点以及是否需要返回头结点一共四种情况。
具体代码实现如下:
Lnode* insert_in_end1(Linklist& L, Lnode* tail, Lnode* p) {
// if know the end node, the pointer to the end node is tail
// return the head node
tail->next = p;
return L;
}
Lnode* insert_in_end2(Linklist& L, Lnode* p) {
// if don't know the end node
// return the head node
Lnode* tail = L;
while (tail->next)
tail = tail->next;
tail->next = p;
return L;
}
void insert_in_end3(Linklist& L, Lnode* tail, Lnode* p) {
// if know the end node, the pointer to the end node is tail
tail->next = p;
}
void insert_in_end4(Linklist& L, Lnode* p) {
// if don't know the end node
Lnode* tail = L;
while (tail->next)
tail = tail->next;
tail->next = p;
}
小结
头插法和尾插法,究其本质而言,都是更改直接前继的next指针指向。
一般来说,可以分为以下几种情况:
- 把原本指向NULL(我们可以把NULL也想象成一个结点)的指向目标结点;
- 往链表中部插入一个结点;
- 让插入结点成为一个新的头节点。
图解
Part II
在Part I中,介绍了和展示了不同情况下头插法和尾插法的源代码。这两种算法比较基础,也是比较简单的。
本文中,我将继续介绍五大算法中的归并法和逆置法。
结点结构定义
typedef struct node {
Elemtype data;
struct node* next;
} Lnode;
具体解释在
Part I中,故不再重复性叙述。
归并法
归并法常常用于排序等场所,但是除了链表以外的数据结构,比如顺序表,也可以使用归并的思想,设计相关的算法。
下面我将按照原本俩链表和结果链表的单调性是否相同分为两种情况,来展示归并具体是一个什么操作,代码的操作实现又是怎么样的。
同样,代码先上为敬。当然啦,如果觉得直接读代码略有些困难,可以把图解啃明白了,再回归代码。
单调性相同
Lnode* merge1(Linklist& LA, Linklist& LB) {
// merge two sorted Singly linked lists
// LA, LB and the return one ( LC ) all have a head node
// all the linklist are sorted in the same way: increasing or decreasing
// we assume that all the slists are sorted in an increasing order
// KEY: insert in the tail
Lnode* LC = (Lnode*)malloc(sizeof(Lnode));
LC->next = NULL;
Lnode *pa = LA->next, *pb = LB->next, *pc = LC;
while (pa && pb) {
if (pa->data < pb->data) {
pc->next = pa;
pa = pa->next;
} else {
pc->next = pb;
pb = pb->next;
}
pc = pc->next;
}
if (pa)
pc->next = pa;
if (pb)
pc->next = pb;
return LC;
}
单调性不同
Lnode* merge2(Linklist& LA, Linklist& LB) {
// merge two sorted Singly linked lists
// LA, LB and the return one ( LC ) all have a head node
// all the linklist are sorted not in the same way:
// LA and LB are the same, but LC just the other way
// we assume that LA and LB are sorted in an increasing order
// KEY: insert in the front
Lnode* LC = (Lnode*)malloc(sizeof(Lnode));
LC->next = NULL;
Lnode *pa = LA->next, *pb = LB->next, *temp = NULL;
while (pa && pb) {
if (pa->data < pb->data) {
temp = pa->next;
pa->next = LC->next;
LC->next = pa;
pa = temp;
} else {
temp = pb->next;
pb->next = LC->next;
LC->next = pb;
pb = temp;
}
}
// only one of the following "while" will be excuted
while (pa) {
temp = pa->next;
pa->next = LC->next;
LC->next = pa;
pa = temp;
}
while (pb) {
temp = pb->next;
pb->next = LC->next;
LC->next = pb;
pb = temp;
}
return LC;
}
归并法图解
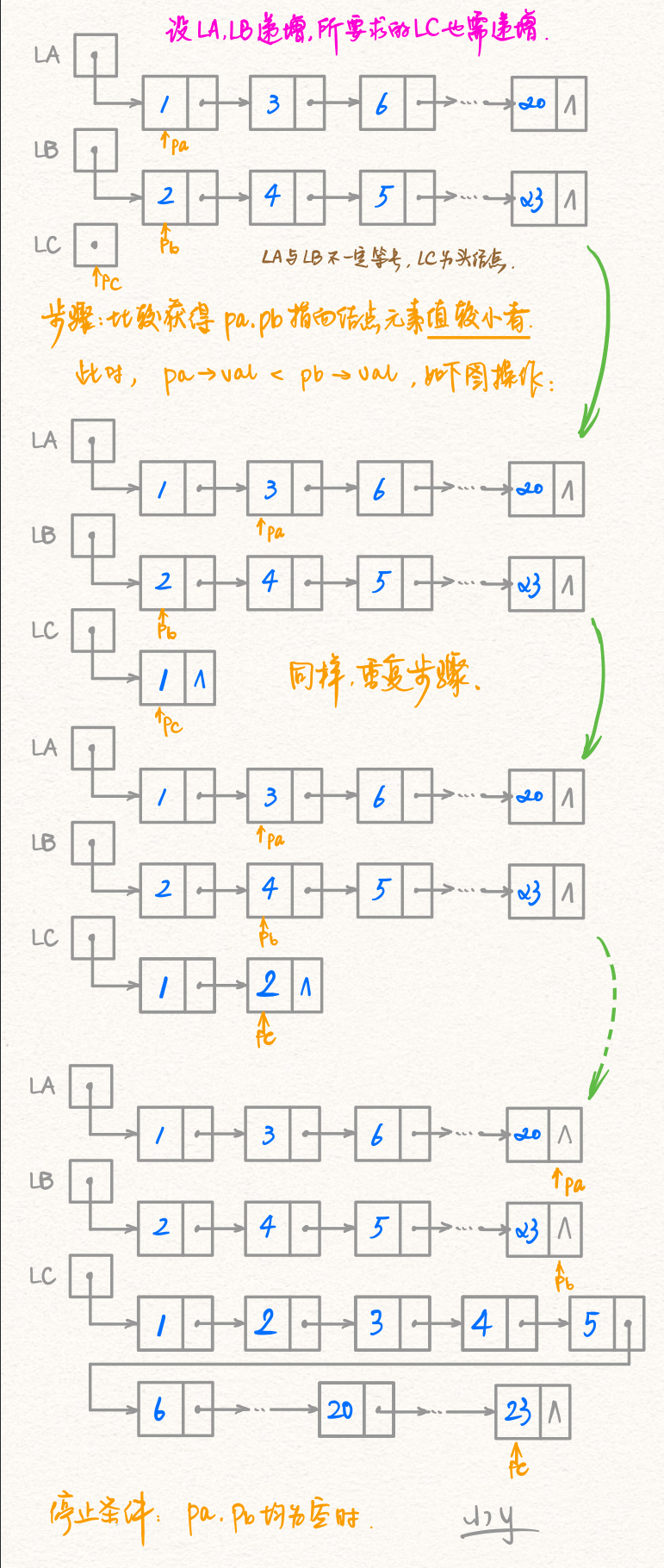
图解仅绘制了LA、LB、LC三条单链表单调性相同时候的情形;
至于LA、LB单调性相同却与LC单调性不同的情况,我们只需要将图中的尾插法改为头插法即可.
头插法和尾插法在上一篇文章中有介绍,也有图解。
小结一波: 单调性相同用尾插法 单调性不同用头插法
逆置法
逆置法:指的是将单链表翻转过来。
例子 有一单链表:1->2->5->4->3 逆置该单链表得到新的链表为:3->4->5->2->1
当然啦,空间复杂度为O(n)的算法自然是很容易想到并且实现的,我们这里就不提这种算法。我们想一想,如何设计一个算法在O(1)的空间复杂度下完成目标任务呢?
下面我就来介绍这种算法。
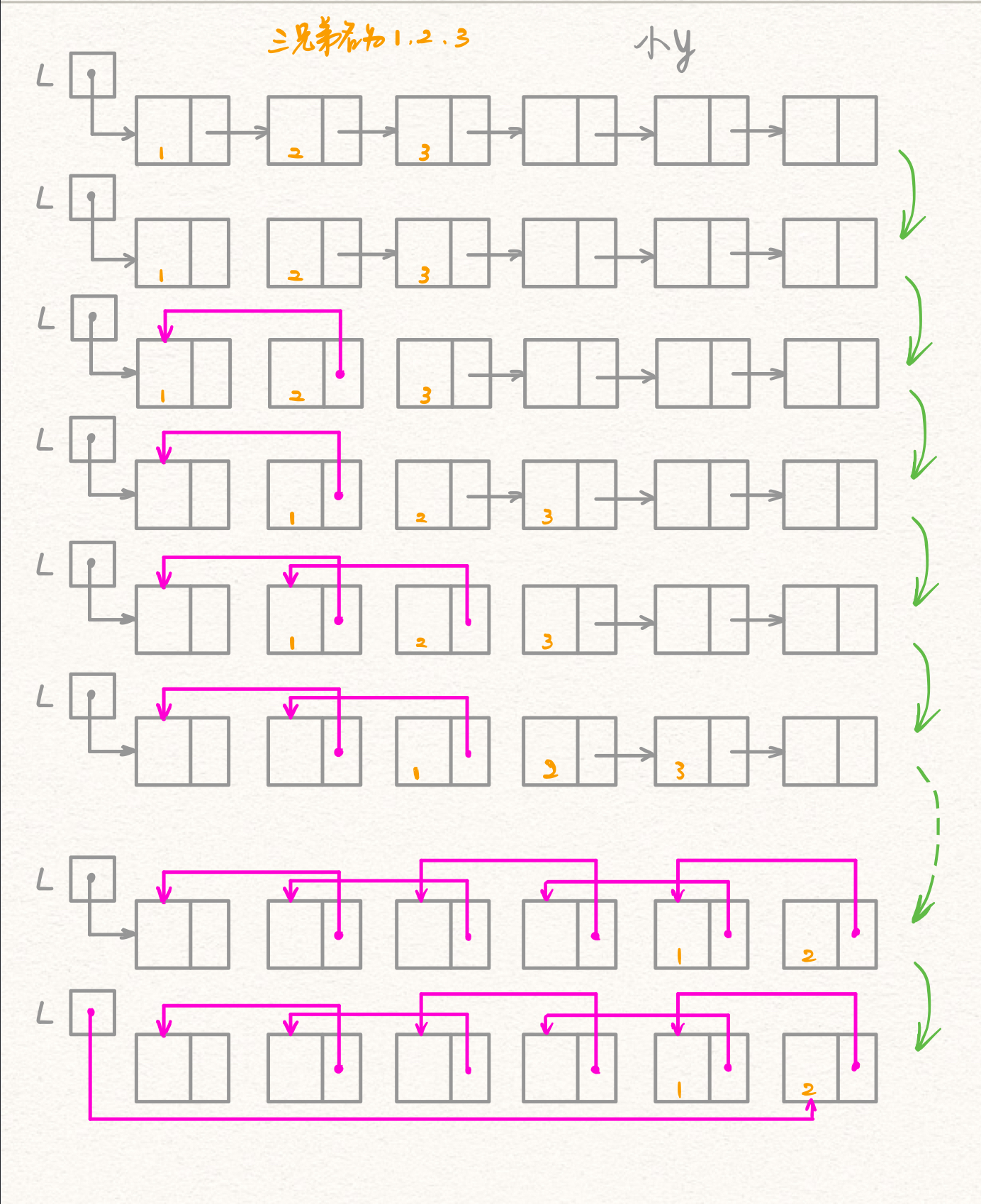
我个人觉得“逆置法”这个官方名字虽然高大上,但是少了些烟火气,不是那么容易被理解。于是我给他起了一个新的名字:三兄弟并排往后走。
要素察觉:三、兄弟、并排、后
四个要素分别对应着:三、指针、并排、(从表头)向后遍历
这里的"并排"有一点
滚动数组的感觉~ 滚动数组又是一个新的概念,后面的文章中会有介绍,这里先让他和大家见个面,混个脸熟~
同样,先上代码,图解具体步骤在后面,有需要的朋友可以先看图解在研究代码。
Lnode* reverseSList(Linklist& L) {
// this is a singly linked list with a head node
// and I name the three brothers: one, two, three
// but we need to face the special situation: there is less than 3 nodes in the list
// so let's talk about it first
Lnode* one, * two, * three;
if (!L->next || !L->next->next) return L; // if there is one node or none, do nothing
one = L->next;
two = one->next;
one->next = NULL;
if (!two->next) { // if three are two nodes
tow->next = one;
L->next = two;
return L;
}
three = two->next;
while (three) { // if three are three or more than three nodes
// three brothers go along the slist until the THREE brother is NULL
two->next = one;
one = two;
two = three;
three = three->next;
}
L->next = two;
return L;
}
逆置法图解
Part III
这部分将完完全全的只介绍一种算法:双指针法。
虽然同为双指针法,但是因其双指针的灵活性,有各种各样的变形,往往不是1+1=2而是1+1>2的效果。
这篇文章将着重阐述双指针在链表中的应用。
为什么
在学习双指针算法之前,我们首先要知道,我们为什么要使用双指针,暴力解决一切问题不好吗?
暴力法常常具有以下特点:思路简单(看到题目第一时间跳出来的算法);程序执行时间长(时间复杂度往往大于双指针的解法)。
举个例子,可能尽管都是O(1)的空间复杂度,可能只是多了一个变量,但是就可以少一次遍历(把2n的时间复杂度降低到n,甚至把O(n^2)降低到O(n)).
看到这里有没有特别好奇,双指针有什么精妙之处,竟有如此大作用?
插一句,在算法中,双指针法是非常基础也非常重要的,不得不学,不得不会。
怎么用
双指针的用法,一般有两种:一是如前面所述降低时间复杂度;二是利用了当前数据结构的某些特性,给出一些巧妙的解法。
下面我们就来看看几个例子,一番操作来探究双指针的用法。
一、固定窗口滑动
第一种用法是固定大小的窗口滑动算法。
例题:给一个单链表,请返回倒数第k个结点。
因为链表并不具备随机存取的特点,没法像顺序表一样以O(1)的时间复杂度获得倒数第k个结点的位置。
如果题目要求正数第k个结点,我们只需要从头结点开始往后走k-1步即可,但是从后往前是不可能滴(因为单链表是顺序存取的->只能从前往后)。
一般做法步骤
- 遍历链表,获得链表长度为
n; - 从头结点开始走
n-k步; - 此时指针指向的就是倒数第
k个结点。
上述做法需要两次遍历,但是如果用了双指针法,效率就会大大提高(时间复杂度从O(2n)讲到O(n));
双指针法步骤
- 右指针
right先沿着链表走k - 1步; - 左指针
left和右指针right同时沿着链表移动; - 当right指向最后一个结点的时候,left指向的就是倒数第k个结点。
因为left和right之间的距离固定,所以这里的双指针算法也叫做
固定长度的滑动窗口。
快慢指针法
第二种用法是快慢指针法。顾名思义,一个指针走得快,一个指针走得慢。
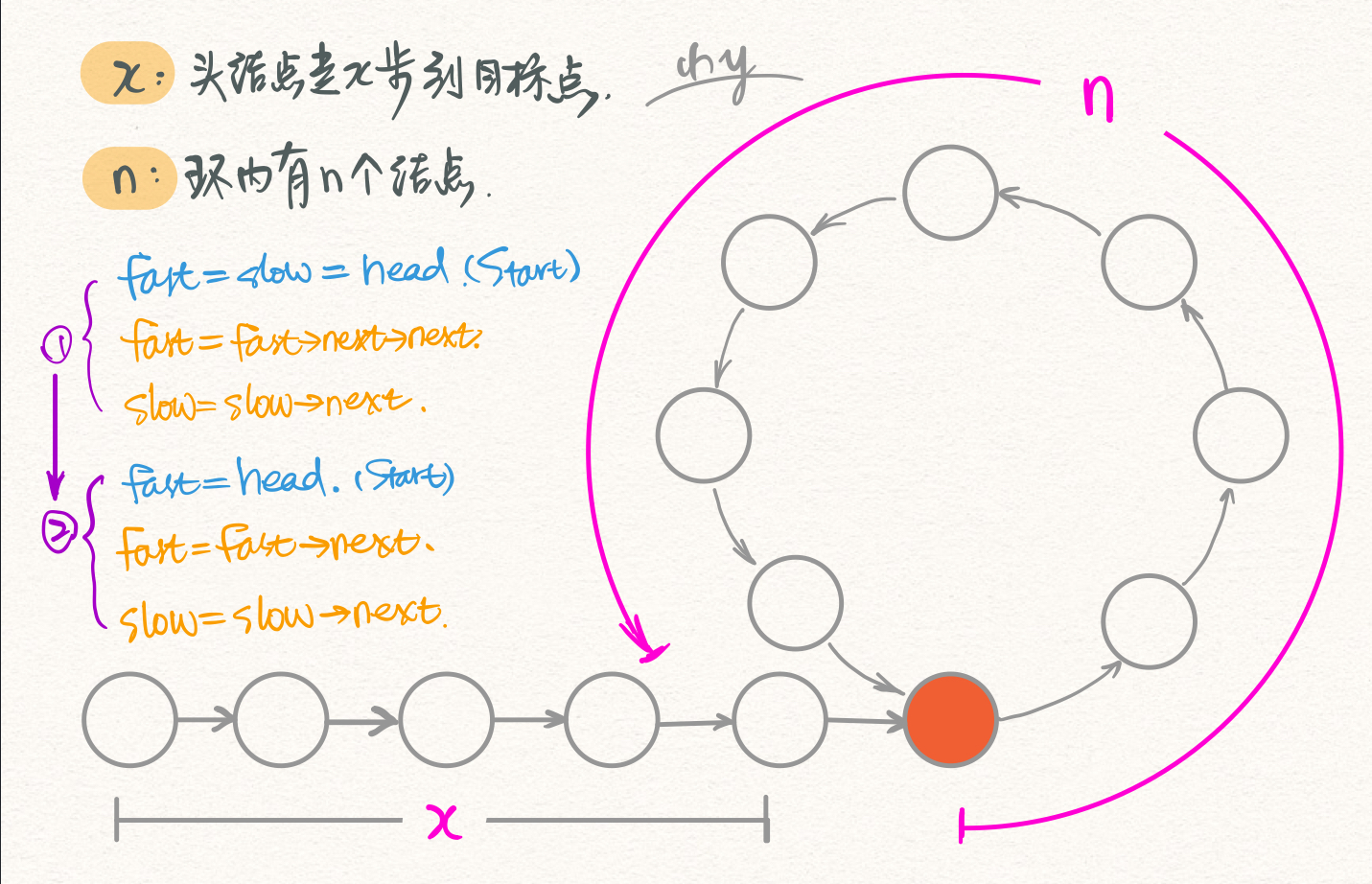
例题:判断一个链表是否有环。 如果有,返回入环的第一个结点; 否则,返回空指针。
这里还是先把代码贴上来。您可以先看看代码,如果不太理解,再看代码后的图解和说明。
Lnode* node_into_circle(Linklist& L) {
Lnode* slow = L, * quick = L;
while (true) {
if (!quick->next || !quick->next->next) return false;
quick = quick->next->next;
slow = slow->next;
if (quick == slow) break;
}
quick = L;
while (quick != slow) {
quick = quick->next;
slow = slow->next;
}
return quick;
}
图解
证明
一般来说,不论是看完代码的你,或是看完了代码以及图解的你,都会一脸懵,为什么这样子就可?
如果你自己就弄明白了这原理,就直接跳过这一小模块吧~
话说,一切严谨的说明都要从数学式子开始,请容我写给你看~
我们假设存在环,且定义几个变量方便表示:
- 快指针在环中第一次追上慢指针的时候,慢指针走了
y步; - 进入环的第一个结点是从头结点顺序往下数的第
x个结点; - 环内的结点个数为
n; - 还有一个任意整数
k。
快慢指针第一次相遇(在相遇前,快指针每次走两步,慢指针每次走一步)的时候,有如下等式:
化简得到
因为y是慢指针此时走的步数,我们通过化简所得可知,慢指针再走x步就可以到达链表入环的第一个结点,而此时我们如果把快结点放到头结点处,和慢指针同样的速度走x步,那么我们就会发现,在慢指针到达目标结点的时候,快指针也到达了目标结点,此时两个指针相遇。
“重新安排了快指针后的第二次相遇”就是我们找到目标结点,退出循环,返回结点的时候。
双指针法
第三种方法也没啥名儿,纯粹是利用了当前数据结构的性质,然后巧用双指针法解决。
例子:两条单链表LA和LB具有公共部分,要求你返回公共部分的第一个结点。如果不具有公共部分,那么就返回空指针。
基础方法
- 遍历
LA,得到长度len_a; - 遍历
LB,得到长度len_b; - 初始化
pa = LA,pb = LB; - 类似
固定长度的窗口滑动,较长链表上的指针先移动abs(len_a - len_b)步; - 然后同时移动
pa和pb,直到两者相等(相遇)。
一眼看下来,我们用了双指针思想啊,现学现用。
但是这题却有另一种更加美丽、善良、让人拍手叫绝的解法。
同样,先放代码,图解和解释放在后面。
进阶方法代码实现
Lnode* find_first_public_node(Linklist& LA, Linklist& LB) {
// LA and LB have a public part
// we need to find the first node in public part and return it
// if without a public part, return NULL
Lnode* pa = LA, * pb = LB;
int lengthA = 0, lengthB = 0, count = 0;
while (pa) {
pa = pa->next;
lengthA++;
count++;
}
while (pb) {
pb = pb->next;
lengthB++;
}
pa = LA; pb = LB;
while (pa != pb && count < lengthA + lengthB) {
pa = pa->next;
pb = pb->next;
count++;
}
if (pa == pb) pa;
else return NULL;
}
具体步骤
- 遍历获得LA的长度
len_a; - 遍历获得LB的长度
len_b; pa = LA, pb = LB;pa遍历LA之后从LB继续遍历,pb遍历LB之后从LA继续遍历- 直到
pa和pb相遇。
这里有一个处理:就是如果
pa或者是pb行走了len_a + len_b步都没有和另一个指针相遇,说明两者并不存在共同部分。如果少了这部分的计数和判断,我们极易写出一个跳不出循环的代码。(如果对此抱有疑问,看下面图解以及证明部分内容。)
图解说明
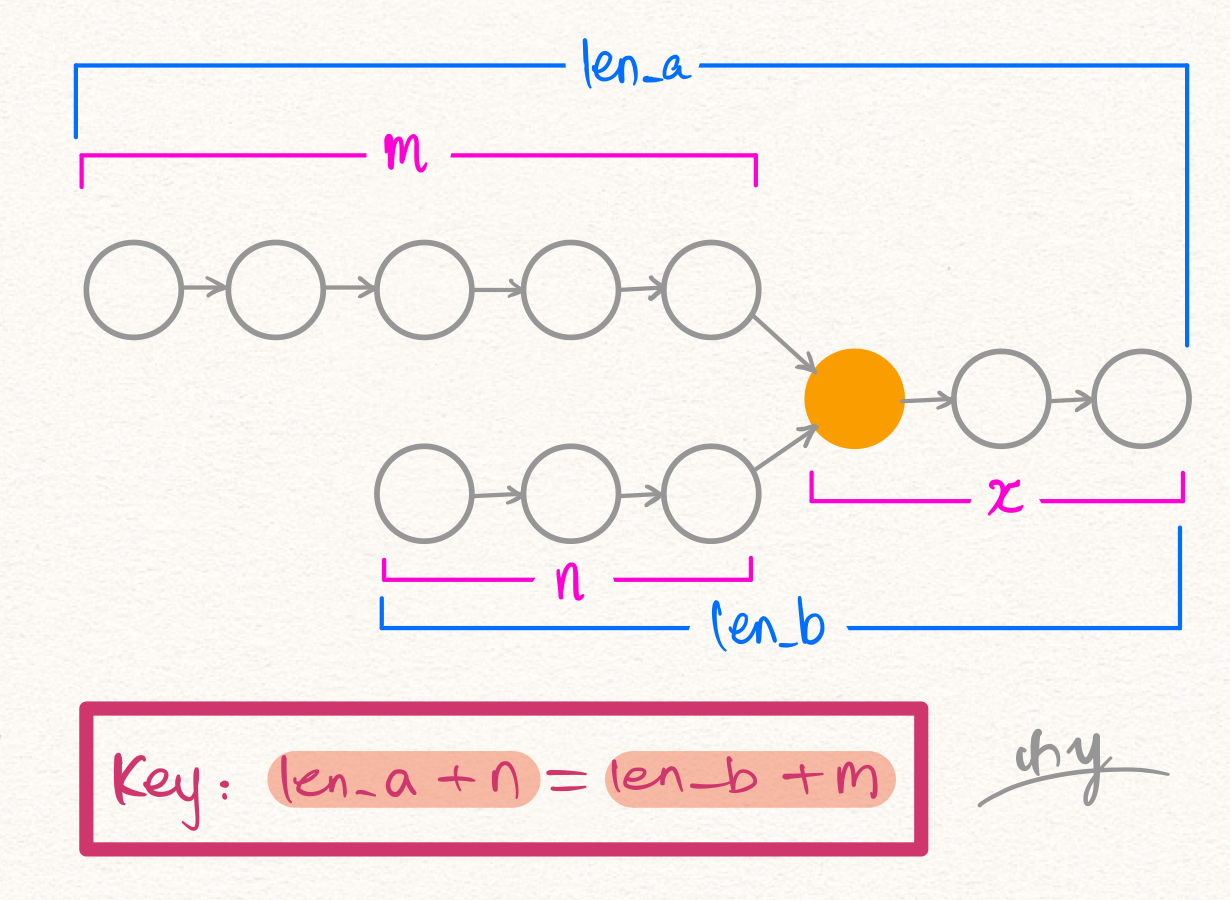
如果LA和LB有公共部分,那么他们的交点必然在某个结点移动了len_a + n(或者len_b + m)时候达到。显然,有不等式
在移动了len_a + len_b都还没找到目标结点,说明我们要找的目标结点根本不存在,也就是两个链表并没有公共部分。
吐槽一下:其实这种方法胜在巧妙,但是执行效率和前面利用了
固定长度的滑动窗口相比,执行效率却是不及:一种遍历两遍以上才可以得到答案(一遍获得长度,一遍多获得目标结点),一种遍历少于等于两遍就可以得到答案(一遍获得长度,一遍少获得目标结点)。但是前者胜在了利用了此结构的特性,对于拓宽我们的思维颇有好处。
