B-tree
Part I
B树,也叫多路平衡查找树。
基本概念
阶:B树中所有结点的孩子个数的最大值,通常用m表示。
定义
一棵m阶B树或为空树,或为满足如下特性的m叉树:
- 树中每个结点至多有m棵子树(最多含有m-1个关键字);
- 如果根结点不是终端结点(叶子结点),则至少有两棵子树;
- 根结点以外的所有非叶结点至少有,
ceil(m/2)棵子树(至少含有ceil(m/2)-1个关键词); - 所有非叶结点的结构如下
图一所示,其中n是结点的关键字个数。是结点的关键字,且为递增序列;
为指向子树根结点的指针。
- 所有的叶结点都出现在同一层上,而且不带信息。
【注】
ceil()函数表示的是向上取整,下同。

指针
所指子树中所有结点的关键字均小于
。
值得注意的是,如果一棵树不满足上面的任何一条性质,就说明他不是B树。 强调这句话的原因是为了B树的插入以及删除操作做个铺垫(尤其要注意n的取值范围)。
B树的高度
也是磁盘的存取次数(这个将在
B树的查找中介绍); B树中大部分操作所需磁盘存取次数与B树的高度成正比。
下面是本小节的正式内容:
一棵包含个关键字、高度为
h、阶数为m的B树,高度h的范围?
既然要得到高度的范围,那么我们显然需要计算高度的两个最值。
计算最小值
如果要使h最小,那么自然要用关键字把每个结点里头塞得满满当当。
既然要塞的满满当当的,自然每个结点里面都要取到关键字个数的最大值,即m-1。下面我们只要得到树高为h时,一共有多少个结点,然后结点个数乘以每个结点中的关键字个数m-1,然后将得到的关键字总数和n比较(自然是要大于等于n的),然后化简一波。
具体计算过程如下:
- 每个结点的关键字个数为:
- 塞满时候结点的总数为:
- 预关键字总数为:
- 而
,化简得
.
计算最大值
如果要使h最大,那么自然要把让每个结点中的关键字个数最小。
这时候,可能会有同学会有疑惑:为了让树的高度最大,为什么我们不能让树状结构直接退化为线性结构呢?单单只是让结点中的关键字个数最小,也没法使h达到最大呀。
如果出现这样子的想法,也很正常,毕竟新接触一个知识点,没办法总是面面俱到。
回到文章的第一句话,我们可以知道:B树是一棵所有结点的平衡因子均等于0的多路平衡查找树。
利用提到过的n的取值范围:,我们知道,这时候,
ceil(m/2)-1要起大作用了。
回顾B树的定义,我们可以知道B树的第一层至少有1个结点,第二层至少有2个结点,第三层至少有2*ceil(m/2)个结点,如此类推,第h+1层至少有个结点(要注意的是
h+1层是不含任何信息的叶结点)。这时候我们反过来想:如果一棵n个关键字的一共有n个关键字,那么查找不成功的结点个数为n+1。于是我们就得到了一个不等式方程,化简之后即为所求。
具体过程如下:
化简即得:
.
不等式方程是如何得到的呢? 试想:查找不成功的结点个数总是要大于等于叶子结点的个数 (我们可以把叶子结点想象成一个区间,每个区间至少有一个查找不成功的结点)
小结
综上,h的范围为
Part II
回想平衡二叉搜索树树的LL、LR、RL、RR,再想想作为多路平衡查找树的B树,我们可以大胆猜想:在B树上进行一些操作的时候,也需要我们不断调整B树,以达到操作之后还是一棵B树的目的。
调整标准
我们需要知道的是,调整的标准是什么(也就是我们应该往哪个方向调整)。
既然我们的调整的目的是使B树仍为一棵B树,所以调整的标准就是B树的定义。
这在文章开头有具体介绍。
其中,在调整过程中,最重要的就是定义的第1、3点。
B树的查找
B树是一棵多路平衡查找树,联想二叉查找树(二叉搜索树),我们可以大概想象一下B树的查找步骤。
但是我们要注意的是,B树和二叉树不同的一点在于,每个结点都是多个关键字组成的有序表,在每个结点上所作的不是两路分支决定,而是根据结点的子树所作的多路分支决定。
基本操作
- 在B树中寻找结点;
- 在结点内找关键字;
B树常存储在磁盘上,因此前一个查找操作是在磁盘上进行的,后一个查找操作是在内存中进行的。
也就是说,在找到目标结点后,先将结点信息读入内存,然后再结点内采用顺序查找或者折半查找(二分查找)。 毫不夸张的说,看到有序表我们就应该想到二分查找,对于有序顺序表上的查找来说,二分查找在降低时间复杂度方面,是个好手。
B树的查找图解
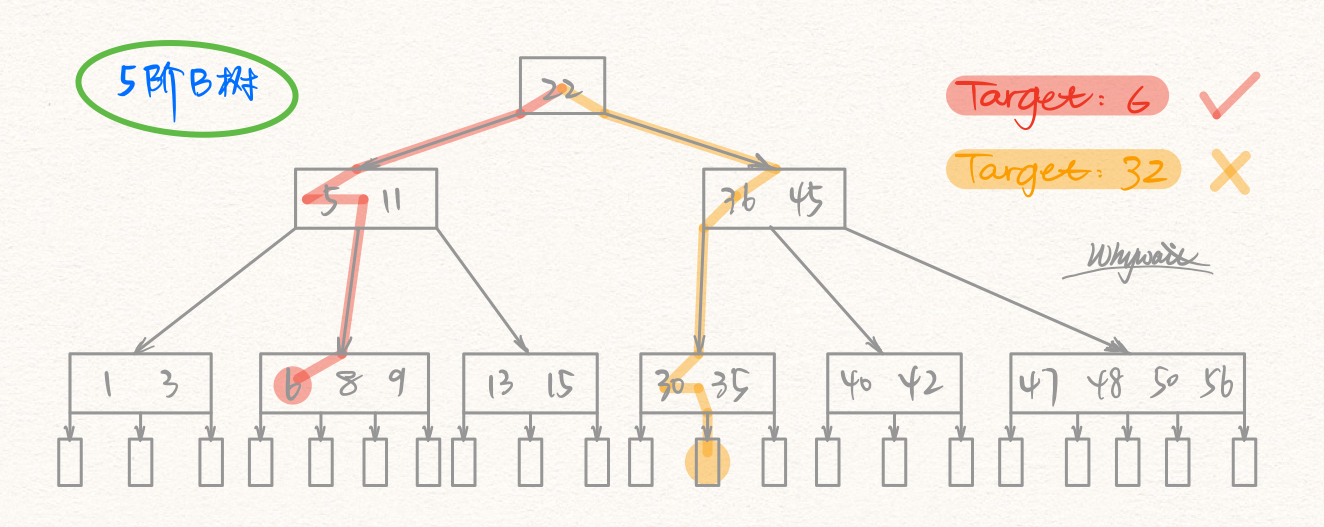
查找,只是从根结点开始,沿着某条路径,在叶结点结束。对树并没有任何修改,所以也不需要调整。
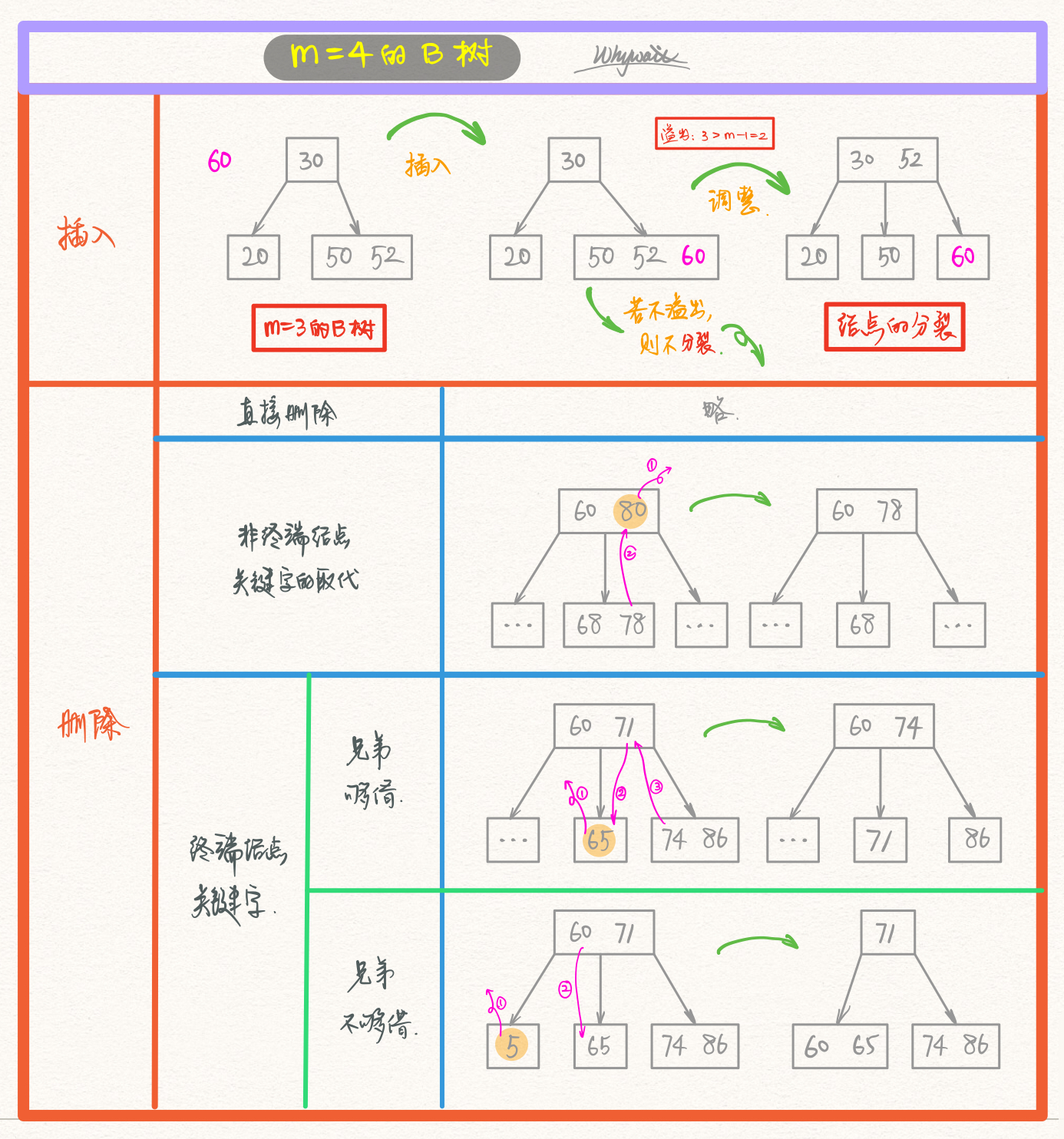
B树的插入
接下来介绍的是B树中关键字的插入和删除操作,在插入和删除操作中,因为涉及了对树的结构的更改,所以在插入和删除之后,我们需要对树的结构进行调整(更加严谨地说,检查并调整本身就是插入和删除操作必不可少的一部分)
插入步骤
第一步:定位:利用查找操作(上文),找出插入该关键字的最低层的某个非叶结点。
第二步:插入:每个非失败结点的关键字个数都在区间[ceil(m / 2) - 1, m - 1]内。
- 如果插入后的关键字个数在上述区间内,直接插入;
- 否则,对结点进行
分裂。
值得注意的是,插入关键字的结点,
是且一定是最底层的某个非叶结点。 还有一点不能忽略:叶结点是查找失败的点。
如何分裂
第一步:取一个新结点,在插入key后的原结点,从中间位置(ceil(m/2))将其中的关键字分为两部分;
- 左部分包含的关键字放在原结点中;
- 右部分包含的关键字放到新结点中;
- 中间位置(
ceil(m/2))的结点插入原结点的父结点。
第二步:如果在将中间位置的结点插入原结点的父结点之后,父结点的关键字也超出上限,那么重复分裂操作,直到这个过程传到根结点为止,进而导致B树的高度增加1。
B树的删除
插入可能要分裂,那么删除自然就可能要合并啦~
合并条件
删除目标关键字后的结点关键字个数小于ceil(m/2) - 1
情况分类
- 往大了说分为两类(关键字是否在终端结点);
- 往小了说分为四类,具体往下看。
第一步:被删关键字k不在终端结点(最底层非叶结点)中时,利用k的前驱或者后继k'来替代k,然后在相应的结点中删除k'。如此这般,将不在终端的情况转换为在终端的情况;
第二步:被删关键字k在终端结点(最底层非叶结点)时:
- 直接删除关键字;
- 兄弟够借(父子换位法);
- 兄弟不够借。
合并过程中,双亲结点中的关键字个数会减一。
- 如果双亲结点是根结点,且关键字个数减少至0,则直接将根结点删除,合并后的新结点成为根;
- 如果双亲结点不是根结点,且关键字个数减少至
ceil(m/2)-2,则需要将此结点与他自己的兄弟结点进行调整或者合并,重复上述操作,直到符合B树的要求。
B树的插入和删除操作详细见下图。