一些主流检测网络的简介
Published:
by
Authur Lee
![]()
- Categories:
- DeepLearning 9
基于深度学习的表面缺陷检测技术
- 基于图像分类网络的表面检测技术
- 基于自编码神经网络的表面缺陷检测技术
- 基于语义分割算法的表面缺陷检测技术
- 基于目标检测算法的表面缺陷检测技术
基于图像分类网络的
通过复杂的多层卷积神经网络进行特征提取,并设计分类器对缺陷进行分类。通过堆叠的卷积层结构捕获图像的高级特征,再通过分类器对缺陷特征进行分类并输出结果。
【缺点】无法对具体缺陷进行定位;当图像中存在多种缺陷时无法输出所有的缺陷类别。
基于自编码神经网络
自编码器使用卷积网络进行特征提取,特点是在后续的缺陷区域分割使用了自编码器模型。
基于语义分割算法
通常可对任意尺寸的图像进行特征提取的操作。【特点】对像素面积较大的目标有较好的分割效果,但对小目标的检测性能不佳;标准工作量是目标检测数据集工作量的数倍。
基于目标检测算法
通常情况,输入的为一张待检测图片,输出一系列检测框坐标及其类别。
主流的目标检测网络
- YOLO系列
- Faster-RCNN网络
- SSD网络
YOLO (You Only Look One)
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon 和Ali Farhadi 等人于2015年提出的基于单个神经网络的目标检测系统。在2017年CVPR上,Joseph Redmon 和 Ali Farhadi 又发表的YOLO 2,进一步提高了检测的精度和速度。
YOLO算法的网络结构
基于GoogleNet,拥有24个卷积层和2个全连接层。和Googlenet不同之处在于,用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules。

网络的输出的最后结果为$7\times 7\times30$大小的张量。此张量代表的含义:对每一个单元格,前20个元素是类别概率值,然后2个元素边界框置信度,最后8个元素是边界框$(x,y,w,h)$;其中前两者相乘为类别置信度。这30个元素都对应一个单元格,其排列可任意,但分类排布会在提取每一个部分的时候更加方便。
网络的预测值是一个二位张量$P$,形状shape为$[\text{batch},7\times 7\times 30]$,那么类别概率部分为$P_{[:,0:7730]}$,置信度部分为$P_{[:,7720:77(20+2)]}$,边框的预测结果为$P_{[:,77(20+2):7730]}$。
YOLO的核心思想
利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
基本流程
- 每个bounding box要预测$(x,y,w,h)$和confidence共 5 个值。
- 每个网格还要预测一个类别信息,一共有$C$类。
- 输入一个图像,首先将图像划分为$S\times S$的网格;
- 对于每个图象,我们都预测$B$个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率);
- 根据上一步可以预测出$S\times S\times B$个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后非极大值抑制处理(Non-Maximum Suppression,NMS)去除冗余窗口即可。
所以,网络的输出结果为一个张量(tensor),其形状为 $S\times S\times (5*B+C)$。
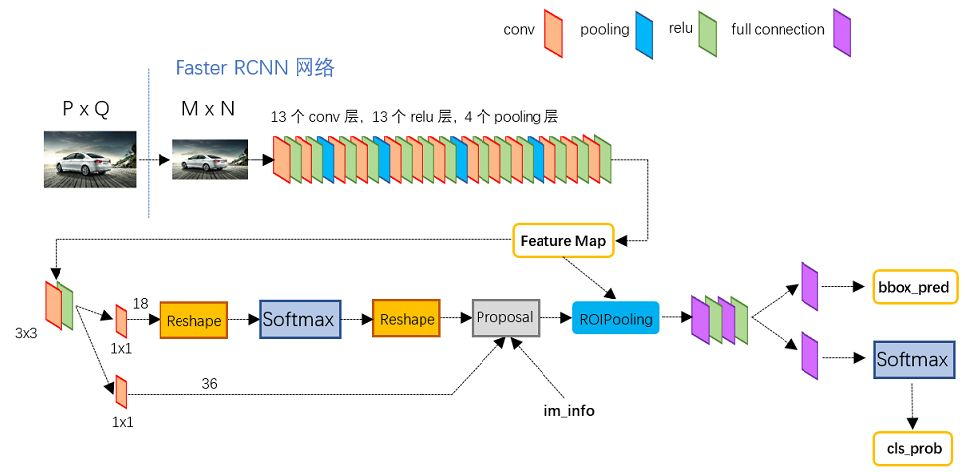
Faster-RCNN
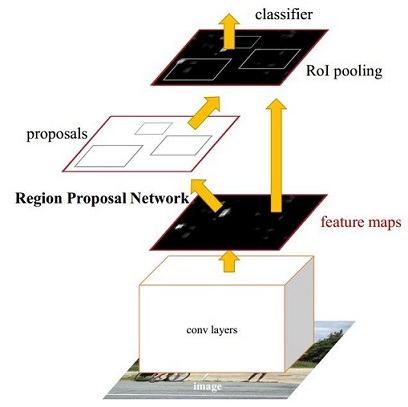
Faster RCNN 主要内容
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
Single Shot MultiBox Detector (SSD)
SSD采用一个CNN网络进行检测(和YOLO相同),采用了多尺度的特征图(和YOLO的不同之处)。
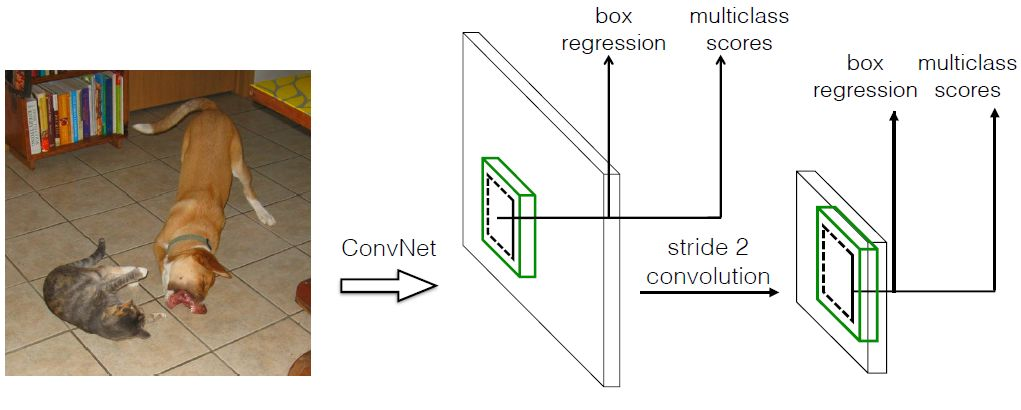
多尺度
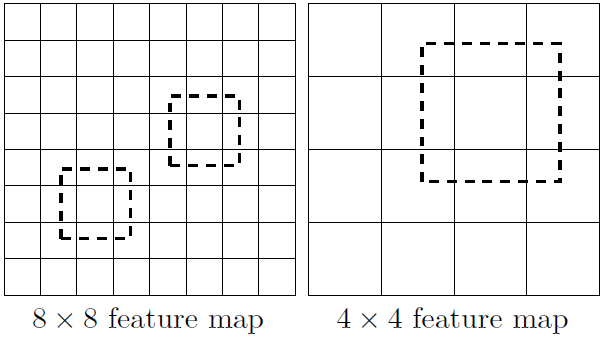
【多尺度特征图用于检测】所谓多尺度,即采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图的大小。如上图所示,一个比较大的特征图和一个比较小的特征图全都拿来做检测。【好处】比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如下图所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。
网络结构
采用VGG16作为基础模型,并在其基础上新增加了卷积层来获得更多的特征图以用于检测。
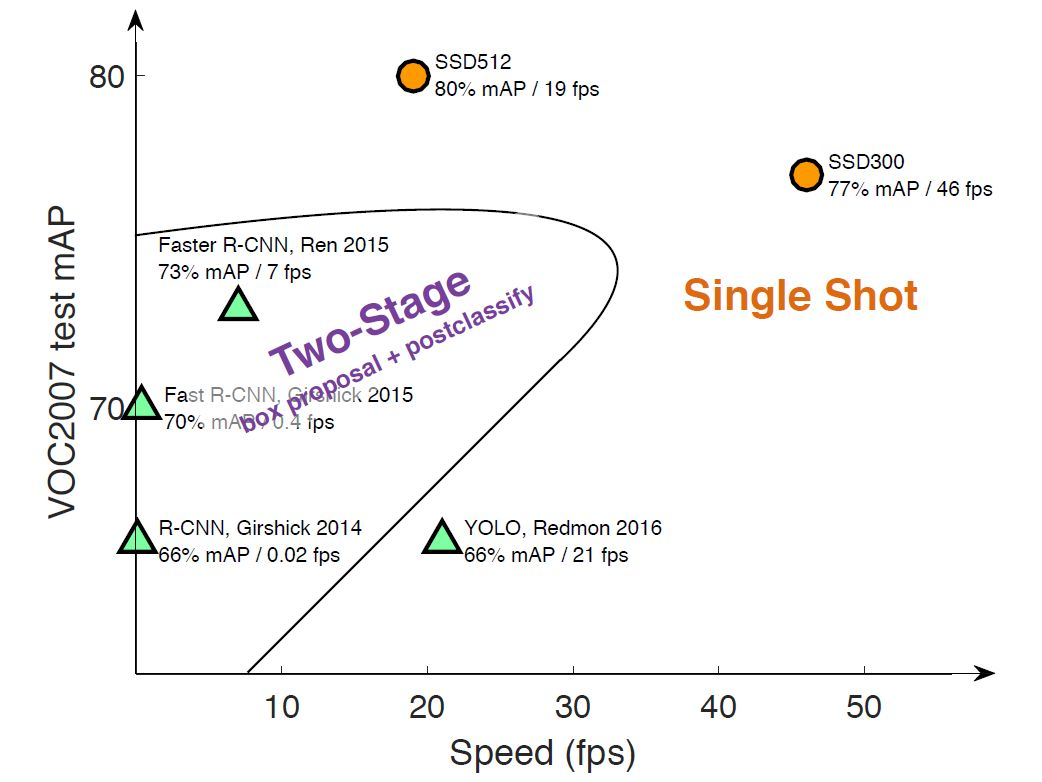
YOLO、R-CNN以及SSD的算法比较