【Code reading】Distilling the knowledge in a neural networks
Github: https://github.com/yeqiwang/KnowledgeDistilling.git
File structure
+ KnowledgeDistilling
+ distillation
+ train_config.py
+ model_structure.py
+ data_load.py
+ distilling.py
+ model_train.py
+ main.py
Distilling
train_config.py
"""
配置文件
"""
# type: Dictionary
# data_config
DATA_CONFIG = {
'batch_size': 256,
'data_shape': (28, 28, 1),
}
# train strategy
TRAIN_CONFIG = {
'lr_schedule': {
'initial_lr': 1e-3,
'decay_step': 2000,
'alpha': 0.1
# teacher alpha 0.01
# student alpha 0.1
},
'epoch': 50,
}
model_structure.py
"""
构建模型
"""
import tensorflow as tf
def TeacherModel():
"""
构建教师模型
:return: 序列化模型
"""
inputs = tf.keras.layers.Input(shape=(28, 28, 1))
# tf.keras.layers.Flatten: Flatten the input. Does not affect the batch size.
x = tf.keras.layers.Flatten()(inputs)
# tf.keras.layers.Dense(units, activation)
# units: postive integer, dimensionality of the output space.
# activation: Activation function to use. If not specify anything,
# no activation is applied. a(x) = x
x = tf.keras.layers.Dense(512, activation='relu')(x)
x = tf.keras.layers.Dense(256, activation='relu')(x)
x = tf.keras.layers.Dense(128, activation='relu')(x)
x = tf.keras.layers.Dense(10)(x)
outputs = tf.keras.layers.Softmax()(x)
# Args of the tf.keras.Model
# inputs: The input(s) of the model: a keras.Input object or list of keras.Input objects.
# outputs: The output(s) of the model. See Functional API example below.
# name: String, the name of the model.
return tf.keras.models.Model(inputs, outputs)
def StudentModel(with_softmax=True):
"""
构建学生模型
:param: 是否加入softmax
:return: 序列化模型
"""
inputs = tf.keras.layers.Input(shape=(28, 28, 1))
x = tf.keras.layers.Flatten()(inputs)
x = tf.keras.layers.Dense(128, activation='relu')(x)
x = tf.keras.layers.Dense(10)(x)
if with_softmax:
x = tf.keras.layers.Softmax()(x)
outputs = x
return tf.keras.models.Model(inputs, outputs)
data_load.py
"""
加载数据
"""
import tensorflow as tf
from distilling import train_config as tc
def _get_fashion_mnist():
"""
加载fashion_mnist数据集
:return:
"""
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 图像归一化
train_images = train_images / 255
test_images = test_images / 255
# reshape增加维度
# shape 后面为两个元组的相加:(1, )为turple,(1)为int
# train_images.shape + (1, ) 为 (60000, 28, 28) + (1, ) 为 (60000, 28, 28, 1)
# 增加维度的原因?TODO:
# print(train_images.shape)
train_images = tf.reshape(train_images, shape=train_images.shape + (1, ))
test_images = tf.reshape(test_images, shape=test_images.shape + (1, ))
# print(train_images.shape)
# 标签one-hot编码
# labels 本为一个n维的向量(n为训练/测试样本数量)
# depth = 10 的原因为此数据集中一共有10类
# 经过tf.one_hot(),向量中的每个元素都变为一个1*10的向量,该向量中对应所属类别上的数值为1,其他元素为0.
# print(train_labels)
train_labels = tf.one_hot(train_labels, depth=10)
test_labels = tf.one_hot(test_labels, depth=10)
# print(train_labels)
return (train_images, train_labels), (test_images, test_labels)
def get_dataset():
"""
获取dataset实例
:return:
"""
# 调用_get_fashion_mnist()函数读取已经被处理过label的train data和test data
(train_images, train_labels), (test_images, test_labels) = _get_fashion_mnist()
# from_tensor_slices(tensor) creates a Dataset whose elements are slices of the given tensors.
# Difference between Dataset.from_tensors and Dataset.from_tensor_slices can be seen here:
# https://stackoverflow.com/questions/49579684/what-is-the-difference-between-dataset-from-tensors-and-dataset-from-tensor-slic
train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
# print((train_images, train_labels))
# print(train_ds)
# train_images.shape[0]为数据集的样本数量
# 如果shuffle的buffer_size=数据集样本数量,则随机打乱整个数据集,例子见
# https://www.cnblogs.com/aimoboshu/p/14567332.html
# idea有点感觉像是堆的感觉,从buffer里面随机抽取样本放到一个batch里面,达到设定的batch_size后新开一个batch存储单元
# “你将会看到shuffle程序将会从dataset中随机生成大小等于buffer_size的样本。”
train_ds = train_ds.cache().shuffle(buffer_size=train_images.shape[0]).batch(tc.DATA_CONFIG['batch_size'])
test_ds = tf.data.Dataset.from_tensor_slices((test_images, test_labels))
test_ds = test_ds.cache().batch(tc.DATA_CONFIG['batch_size'])
return train_ds, test_ds
distilling.py
"""
知识蒸馏
"""
import tensorflow as tf
class Distilling(tf.keras.models.Model):
def __init__(self, student_model=None, teacher_model=None, **kwargs):
super(Distilling, self).__init__(**kwargs)
self.student_model = student_model
self.teacher_model = teacher_model
# T is the temperature of knowledge distillation
self.T = 0.
self.alpha = 0.
self.clf_loss = None
self.kd_loss = None
# Computes the (weighted) mean of the given values.
self.clf_loss_tracker = tf.keras.metrics.Mean(name='clf_loss')
self.kd_loss_tracker = tf.keras.metrics.Mean(name='kd_loss')
self.sum_loss_tracker = tf.keras.metrics.Mean(name='sum_loss')
def compile(self, clf_loss=None, kd_loss=None, T=0., alpha=0., **kwargs):
super(Distilling, self).compile(**kwargs)
self.clf_loss = clf_loss
self.kd_loss = kd_loss
self.T = T
self.alpha = alpha
@property
def metrics(self):
metrics = [self.sum_loss_tracker, self.clf_loss_tracker, self.kd_loss_tracker]
# 列表相加,其实是为列表的拼接
# TODO: self.compiled_metrics 从哪里来?
if self.compiled_metrics is not None:
metrics += self.compiled_metrics.metrics
return metrics
def train_step(self, data):
x, y = data
# tf.GradientTape(): Record operations for automatic differentiation.
with tf.GradientTape() as tape:
# 学生模型的逻辑单元
logits_pre = self.student_model(x)
# 教师模型软目标
t_logits_pre = self.teacher_model(x, training=False)
# 学生损失
clf_loss_value = self.clf_loss(y, tf.math.softmax(logits_pre))
# 蒸馏损失
kd_loss_value = self.kd_loss(tf.math.softmax(t_logits_pre/self.T), tf.math.softmax(logits_pre/self.T))
# 总损失 = alpha * 学生损失 + (1 - alpha) * 蒸馏损失
sum_loss_value = self.alpha * clf_loss_value + (1-self.alpha) * kd_loss_value
# Calling minimize() takes care of both computing the gradients and applying them to the variables.
# If you want to process the gradients before applying them you can instead use the optimizer in three steps:
# 1. Compute the gradients with tf.GradientTape.
# 2. Process the gradients as you wish.
# 3. Apply the processed gradients with apply_gradients().
self.optimizer.minimize(sum_loss_value, self.student_model.trainable_variables, tape=tape)
# update the state of labels and softmax of logits_prediction
self.compiled_metrics.update_state(y, tf.math.softmax(logits_pre))
self.sum_loss_tracker.update_state(sum_loss_value)
self.clf_loss_tracker.update_state(clf_loss_value)
self.kd_loss_tracker.update_state(kd_loss_value)
return {m.name: m.result() for m in self.metrics}
def test_step(self, data):
# compared with the train_step function, the optimizer.minimize() is gone.
x, y = data
logits_pre = self.student_model(x, training=False)
t_logits_pre = self.teacher_model(x, training=False)
clf_loss_value = self.clf_loss(y, tf.math.softmax(logits_pre))
kd_loss_value = self.kd_loss(tf.math.softmax(t_logits_pre / self.T), tf.math.softmax(logits_pre / self.T))
sum_loss_value = self.alpha * clf_loss_value + (1 - self.alpha) * kd_loss_value
self.compiled_metrics.update_state(y, tf.math.softmax(logits_pre))
self.sum_loss_tracker.update_state(sum_loss_value)
self.clf_loss_tracker.update_state(clf_loss_value)
self.kd_loss_tracker.update_state(kd_loss_value)
return {m.name: m.result() for m in self.metrics}
model_train.py
import tensorflow as tf
from distilling import train_config as tc
from distilling import data_load, model_sturcture, distilling
def clf_train(model_name: str, model_path, tb_path):
"""
模型训练
:return:
"""
train_ds, test_ds = data_load.get_dataset()
# tf.keras.optimizers.schedules.CosineDecay: A LearningRateSchedule that uses a cosine decay schedule.
# parameters are read from the configurations of our learing rate schedule
cosine_lr_schdule = tf.keras.optimizers.schedules.CosineDecay(
initial_learning_rate=tc.TRAIN_CONFIG['lr_schedule']['initial_lr'],
decay_steps=tc.TRAIN_CONFIG['lr_schedule']['decay_step'],
alpha=tc.TRAIN_CONFIG['lr_schedule']['alpha'],
)
# choose to train our model on different datasets with corresponding structure of our models
if model_name == 'teacher':
model = model_sturcture.TeacherModel()
else:
# Softmax layers exit since the model trained on student dataset is leaning without the knowledge from the teacher model
model = model_sturcture.StudentModel(with_softmax=True)
# The model.compile() method is used when configuring the optimizer, loss, and metrics that will be used during training.
model.compile(
# the optimizer that implements the Adam algorithm is used
optimizer=tf.keras.optimizers.Adam(learning_rate=cosine_lr_schdule, amsgrad=True),
# computes the cross entropy loss between the labels and predictions
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
# Calculates how often predictions match one-hot labels.
# 'acc' is the string name of the metric instance
metrics=[
tf.keras.metrics.CategoricalAccuracy('acc'),
]
)
my_callbacks = [
# Enable visualizations for TensorBoard.
tf.keras.callbacks.TensorBoard(log_dir=tb_path, histogram_freq=1),
# Stop training when a monitored metric has stopped improving.
# patience: Number of epochs with no improvement after which training will be stopped.
# monitor: Quantity to be monitored.
# restore_best_weights: Whether to restore model weights from the epoch with the best value of the monitored quantity.
tf.keras.callbacks.EarlyStopping(patience=5, monitor='val_loss', restore_best_weights=True)
]
# Train the model for a given number of rounds (iterations over the dataset)
# verbose: 0, 1, 2. 日志显示模式。0安静模式,1进度条,2每轮一行
model.fit(x=train_ds, epochs=tc.TRAIN_CONFIG['epoch'], callbacks=my_callbacks, validation_data=test_ds, verbose=1)
# Keras model provides this function, evaluate which returns the loss value & metrics values for the model in test mode.
# It has three main arguments: data, label, and verbose
# Details in https://keras.io/api/models/model_training_apis/
# print
# 235/235 [==============================] - 1s 4ms/step - loss: 0.2492 - acc: 0.9121
# 40/40 [==============================] - 0s 3ms/step - loss: 0.3300 - acc: 0.8799
model.evaluate(train_ds)
model.evaluate(test_ds)
model.save_weights(model_path)
def distilling_train(model_name:str, model_path, tb_path):
train_ds, test_ds = data_load.get_dataset()
cosine_lr_schdule = tf.keras.optimizers.schedules.CosineDecay(
initial_learning_rate=tc.TRAIN_CONFIG['lr_schedule']['initial_lr'],
decay_steps=tc.TRAIN_CONFIG['lr_schedule']['decay_step'],
alpha=tc.TRAIN_CONFIG['lr_schedule']['alpha'],
)
teacher_model = model_sturcture.TeacherModel()
teacher_model.load_weights('./cheakpoint/teacher/')
# get_layer(name=None, index=None) will return a layer instance.
# Here, the layer returned will be the penultimate layer of the network
# layer and layer.output
# print(teacher_model.get_layer(index=-2))
# <keras.layers.core.dense.Dense object at 0x7f8894f7e750>
# print(teacher_model.get_layer(index=-2).output)
# KerasTensor(type_spec=TensorSpec(shape=(None, 10), dtype=tf.float32, name=None), name='dense_3/BiasAdd:0', description="created by layer 'dense_3'")
teacher_model = tf.keras.Model(teacher_model.inputs, teacher_model.get_layer(index=-2).output)
student_model = model_sturcture.StudentModel(with_softmax=False)
dist = distilling.Distilling(student_model=student_model, teacher_model=teacher_model)
dist.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=cosine_lr_schdule, amsgrad=True),
clf_loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
kd_loss=tf.keras.losses.KLDivergence(),
T=2,
alpha=0.9,
metrics=[
tf.keras.metrics.CategoricalAccuracy('acc')
]
)
my_callbacks = [
tf.keras.callbacks.TensorBoard(log_dir=tb_path, histogram_freq=1),
tf.keras.callbacks.EarlyStopping(patience=5, monitor='val_clf_loss', restore_best_weights=True)
]
dist.fit(x=train_ds, epochs=tc.TRAIN_CONFIG['epoch'], callbacks=my_callbacks, validation_data=test_ds, verbose=1)
dist.evaluate(train_ds)
dist.evaluate(test_ds)
main.py
import datetime
from distilling import model_train
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='manual to this script')
# 加入一个参数,选择训练的类型
parser.add_argument('--model', type=str, default='teacher')
args = parser.parse_args()
tb_path = './tensorboard/{}/'.format(args.model)
model_path = './cheakpoint/{}/'.format(args.model)
if args.model == 'teacher' or args.model == 'student':
model_train.clf_train(model_name=args.model, tb_path=tb_path, model_path=model_path)
if args.model == 'distilling':
model_train.distilling_train(model_name=args.model, tb_path=tb_path, model_path=model_path)
# teacher 0.8938
# student 0.8718
Related knowledge
Cosine decay schedule
- global_step = min(global_step, decay_steps)
- cosine_decay = 0.5 * (1 + cos(pi * global_step / decay_steps))
- decayed = (1 - alpha) * cosine_decay + alpha
- decayed_learning_rate = learning_rate * decayed
Here, alpha can be treated as a baseline, which is applied to guaranteed the learning rate will always be no less than a certain value.
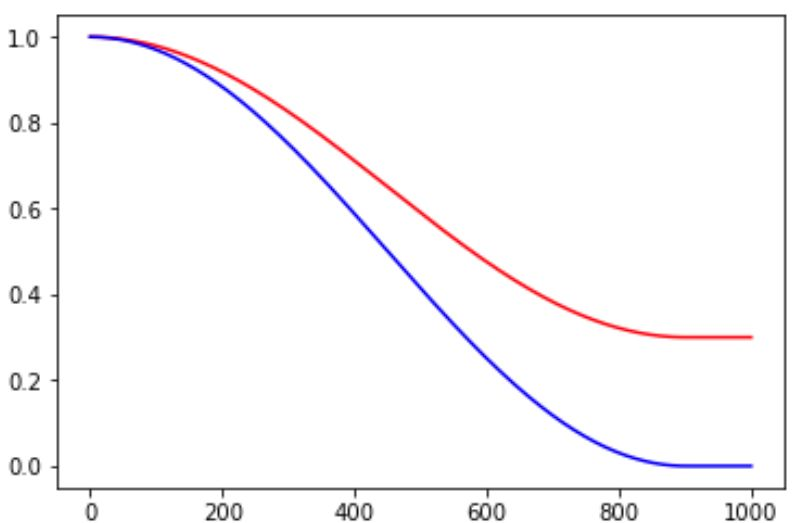
Other learning rate decay strategy in Tensorflow can be found HERE.
Adam optimization algorithm
Introduced HERE in the previous blog.
The authors describe Adam as combining the advantages of two other extensions of stochastic gradient descent. Specifically:
- Adaptive Gradient Algorithm (AdaGrad) that maintains a per-parameter learning rate that improves performance on problems with sparse gradients (e.g. natural language and computer vision problems).
- Root Mean Square Propagation (RMSProp) that also maintains per-parameter learning rates that are adapted based on the average of recent magnitudes of the gradients for the weight (e.g. how quickly it is changing). This means the algorithm does well on online and non-stationary problems (e.g. noisy).
Adam realizes the benefits of both AdaGrad and RMSProp.
Python @property decorator
https://www.programiz.com/python-programming/property
References
- https://www.tensorflow.org/api_docs/python/tf
- https://zhuanlan.zhihu.com/p/32923584
- https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
- https://download.csdn.net/download/weixin_38738977/12850766?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-download-2%7Edefault%7ECTRLIST%7EFeaturesSort-1-12850766-blog-82148497.topnsimilarv1&depth_1-utm_source=distribute.pc_relevant_t0.none-task-download-2%7Edefault%7ECTRLIST%7EFeaturesSort-1-12850766-blog-82148497.topnsimilarv1&utm_relevant_index=1
- https://keras.io/api/models/model_training_apis/
- https://www.programiz.com/python-programming/property